# paquetes ----------------------------------------------------------------
library(tidyverse)
library(glue)
library(here)
library(ggtext)
library(showtext)
# fuentes -----------------------------------------------------------------
font_add_google(name = "Libre Bodoni", family = "libre", db_cache = FALSE) # título
font_add_google(name = "Nunito Sans", family = "nunito") # resto del texto
font_add_google(name = "Share Tech Mono", family = "share") # números
showtext_auto()
showtext_opts(dpi = 300)
# íconos
font_add("fa-reg", here("icon/Font Awesome 5 Free-Regular-400.otf"))
font_add("fa-brands", here("icon/Font Awesome 5 Brands-Regular-400.otf"))
font_add("fa-solid", here("icon/Font Awesome 5 Free-Solid-900.otf"))
# datos -------------------------------------------------------------------
age_gaps <- readr::read_csv('https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2023/2023-02-14/age_gaps.csv')
# actores ----
# top 100 male, actor 1
top_100_m_1 <- age_gaps |>
filter(character_1_gender == "man") |>
# agrupo por película, por si hay múltiples parejas
group_by(movie_name) |>
distinct(actor_1_name) |>
ungroup() |>
# ordeno por cantidad y tomo los primeros 100
count(actor_1_name, sort = TRUE) |>
slice(1:100) |>
pull(actor_1_name)
# con los actores, verifico actor 1&2
top_m <- bind_rows(
age_gaps |>
filter(actor_1_name %in% top_100_m_1),
age_gaps |>
filter(actor_2_name %in% top_100_m_1)) |>
# selecciono columnas de interés y renombro
select(movie_name, release_year, age_difference, actor_1_name, actor_2_name,
actor_1_age, actor_2_age)
# si el actor es mayor, la diferencia es positiva
# si el actor es menor, la diferencia es negativa
datos_m <- top_m |>
mutate(age_difference = case_when(actor_1_name %in% top_100_m_1 ~ age_difference,
TRUE ~ -age_difference)) |>
mutate(ac = if_else(age_difference >= 0, actor_1_name, actor_2_name)) |>
# elijo solamente el top 100 m
filter(ac %in% top_100_m_1) |>
group_by(ac) |>
# obtengo la diferencia de edad media (con signo)
summarise(delta = mean(age_difference), .groups = "drop") |>
# ordeno los actores por delta
mutate(ac = fct_reorder(ac, delta)) |>
arrange(ac) |>
rename(ac1 = ac, delta1 = delta)
# actrices ----
# top 5 female 1
top_100_f_1 <- age_gaps |>
filter(character_2_gender == "woman") |>
# agrupo por película, por si hay múltiples parejas
group_by(movie_name) |>
distinct(actor_2_name) |>
ungroup() |>
# ordeno por cantidad y tomo los primeros 100
count(actor_2_name, sort = TRUE) |>
slice(1:100) |>
pull(actor_2_name)
# con las actrices, verifico actriz 1&2
top_f <- bind_rows(
age_gaps |>
filter(actor_1_name %in% top_100_f_1),
age_gaps |>
filter(actor_2_name %in% top_100_f_1)) |>
# selecciono columnas de interés y renombro
select(movie_name, release_year, age_difference, actor_1_name, actor_2_name,
actor_1_age, actor_2_age)
# si la actriz es mayor, la diferencia es positiva
# si la actriz es menor, la diferencia es negativa
datos_f <- top_f |>
mutate(age_difference = case_when(actor_1_name %in% top_100_f_1 ~ age_difference,
TRUE ~ -age_difference)) |>
mutate(ac = if_else(age_difference >= 0, actor_1_name, actor_2_name)) |>
# elijo solamente el top 100 f
filter(ac %in% top_100_f_1) |>
group_by(ac) |>
# obtengo la diferencia de edad media (con signo)
summarise(delta = mean(age_difference), .groups = "drop") |>
# ordeno los actores por delta
mutate(ac = fct_reorder(ac, delta)) |>
arrange(ac) |>
rename(ac2 = ac, delta2 = delta)
# combino ambos datos
f_m <- bind_cols(datos_f, datos_m)
# figura ------------------------------------------------------------------
# colores ppales
c_m <- "#fb9e4f"
c_f <- "#9dd893"
# caption
icon_twitter <- "<span style='font-family:fa-brands; color:white;'></span>"
icon_github <- "<span style='font-family:fa-brands; color:white;'></span>"
fuente <- "<span style='color:grey90;'>Datos:</span> <span style='color:gold;'><span style='font-family:mono;'>{**tidytuesdayR**}</span> semana 7</span>"
autor <- "<span style='color:grey90;'>Autor:</span> <span style='color:gold;'>**Víctor Gauto**</span>"
sep <- "<span style = 'color:#a4cac8;'>**|**</span>"
usuario <- "<span style = 'color:gold;'>**vhgauto**</span>"
mi_caption <- glue("{fuente} {sep} {autor} {sep} {icon_github} {icon_twitter} {usuario}")
# plot
g1 <- ggplot(data = f_m, aes(y = as.numeric(ac2))) +
# vertical en age_gap == 0
geom_vline(xintercept = 0, color = "gold", linewidth = 1, alpha = 1,
linetype = 2) +
# actores
geom_point(aes(x = delta1), color = c_m, shape = 16) +
# actrices
geom_point(aes(x = delta2), color = c_f, shape = 18) +
# manual
scale_x_continuous(labels = scales::label_number(style_positive = "plus",
style_negative = "hyphen"),
limits = c(-30, 30),
expand = c(0, 0),
# segundo eje horizontal arriba
sec.axis = dup_axis(name = NULL)) +
scale_y_continuous(breaks = 1:nrow(f_m),
labels = f_m$ac2,
expand = c(0, 0),
# segundo eje vertical a la derecha
sec.axis = sec_axis(~ .,
breaks = 1:nrow(f_m),
labels = f_m$ac1)) +
coord_cartesian(clip = "off") +
# ejes
labs(y = NULL,
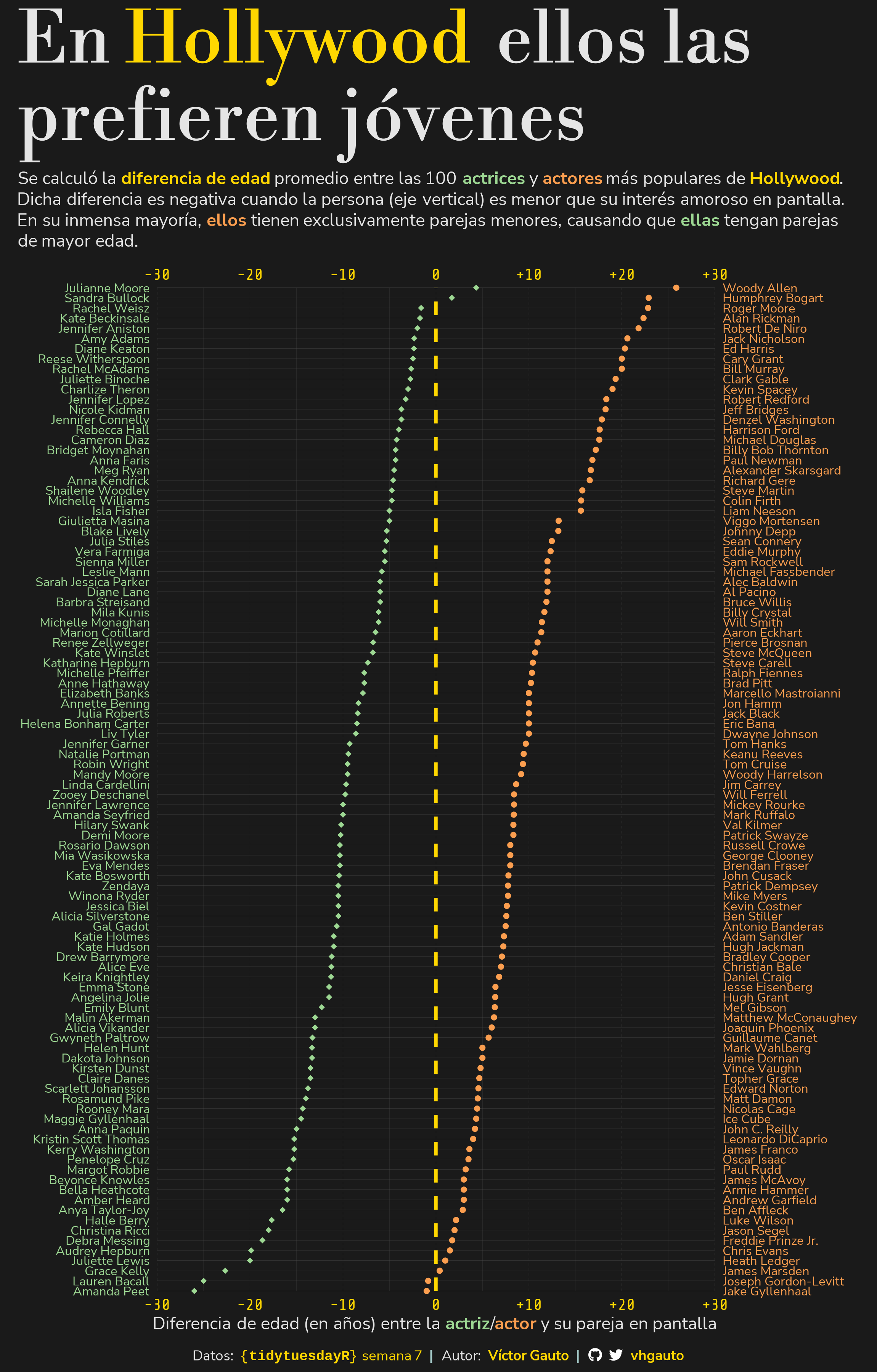
x = glue(
"Diferencia de edad (en años) entre la
<span style='color:{c_f}'>**actriz**</span>/<span style='color:{c_m}'>**actor**</span>
y su pareja en pantalla"),
title = "En <span style='color:gold;'>Hollywood </span> ellos las<br>
prefieren jóvenes",
subtitle = glue(
"Se calculó la <span style='color:gold;'>**diferencia de
edad**</span> promedio entre las 100
<span style='color:{c_f};'>**actrices**</span>
y <span style='color:{c_m};'>**actores**</span> más populares de
<span style='color:gold;'>**Hollywood**</span>. Dicha diferencia es
negativa cuando la persona (eje vertical) es menor que su interés
amoroso en pantalla. En su inmensa mayoría,
<span style='color:{c_m};'>**ellos**</span> tienen exclusivamente
parejas menores, causando que <span style='color:{c_f};'>**ellas**</span>
tengan parejas de mayor edad."),
caption = mi_caption,) +
theme_minimal() +
theme(aspect.ratio = 1.8,
axis.text.x = element_text(color = "gold", family = "share",
size = 10, face = "bold"),
axis.text.y.left = element_text(color = c_f, family = "nunito",
size = 8),
axis.text.y.right = element_text(color = c_m, family = "nunito",
size = 8),
axis.title.x.bottom = element_markdown(color = "grey90", family = "nunito"),
panel.grid.minor.y = element_blank(),
panel.grid.major.y = element_line(linewidth = .05, color = "grey30"),
panel.grid.major.x = element_line(linewidth = .05, color = "grey30",
linetype = "ff"),
panel.grid.minor.x = element_line(linewidth = .03, color = "grey30"),
panel.background = element_rect(fill = "grey10", color = NA),
plot.background = element_rect(fill = "grey10", color = NA),
plot.title = element_markdown(size = 45, family = "libre",
color = "grey90"),
plot.title.position = "plot",
plot.subtitle = element_textbox_simple(color = "grey90",
family = "nunito",
margin = margin(0, 0, 10, 0)),
plot.caption = element_markdown(hjust = .5, family = "nunito",
margin = margin(10, 0, 0, 0)),
plot.caption.position = "plot")
# guardo
ggsave(plot = g1,
filename = here("2023/semana_07/viz.png"),
width = 2300,
height = 3600,
units = "px",
dpi = 300)
# abro
browseURL(here("2023/semana_07/viz.png"))